


Data is everywhere – streaming from mobile apps, IoT sensors, websites, digital payments, CRM systems, enterprise applications, and analytics platforms. But while businesses generate huge volumes of data daily, only a fraction of it actually becomes usable. That’s the real challenge.
In the past, organizations relied on manual data transfers, outdated scripts, and isolated systems that didn’t communicate with each other. The result? Delays, inconsistent reports, data loss, and flawed insights. As technology and customer demands advanced, this approach quickly became too slow and too inaccurate to support modern decisions..
Today, the landscape has changed. With AI, automation, cloud computing, and big data, companies need reliable, scalable data pipelines to move, process, and transform information in real time. These pipelines act as the connective tissue – the central nervous system – that empowers analytics, machine learning, reporting, and digital experiences.
This article is your 2025-ready guide to understanding and building data pipelines that actually work.
What Are Data Pipelines? (Simple Definition)
A data pipeline is a structured process that automatically collects data from multiple sources, moves it to a destination system, and transforms it into a usable format for analysis, reporting, or machine learning.
Think of it like a water pipeline — except it carries information instead of liquid.
Core Functions of a Data Pipeline
- Collecting raw data from different platforms
- Validating and cleaning data
- Performing transformations and enrichment
- Loading into storage (warehouse, data lake, database)
- Making data ready for analytics or automation
Where Data Pipelines Are Used
- E-commerce sales and inventory tracking
- Banking and digital payments fraud monitoring
- Healthcare patient data analytics
- Social media recommendation algorithms
- Smart factories and IoT monitoring
Why Data Pipelines Matter in 2025
Current Challenges Driving Adoption
| Issue | Why It’s a Problem |
|---|---|
| Rising data volume | Manual workflows can’t keep up |
| Multi-channel ecosystems | Data arrives in different formats & speeds |
| Real-time expectations | Customers want instant responses |
| AI + Machine Learning | Require structured, high-quality data |
| Compliance & Governance | Errors = penalties & lost trust |
Without data pipelines, companies risk:
Slow insights
Inconsistent reports
Missed revenue opportunities
Poor customer experience
With pipelines:
Automation replaces manual work
Faster decisions, smarter automation
AI-ready data quality
Unified business intelligence
SEO keywords included naturally: data pipelines, data engineering, ETL, ELT, cloud data pipelines, data warehouse, big data workflow, data streaming.
Types of Data Pipelines
1. Batch Processing Pipelines
- Data is collected and processed at scheduled intervals
- Best for: daily reports, payroll systems, sales summaries
Example: Processing website analytics every night.
2. Real-Time (Streaming) Pipelines
- Data moves continuously and is processed instantly
- Best for: fraud detection, IoT monitoring, live dashboards
Example: Netflix or YouTube recommending content dynamically.
3. ETL vs ELT Pipelines
| Feature | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| Processing Style | Pre-transform before storage | Transform inside destination |
| Best For | Traditional databases | Cloud data warehouses |
| Speed | Slower | Faster, scalable |
| Tools | Informatica, Talend | Snowflake, BigQuery, Databricks |
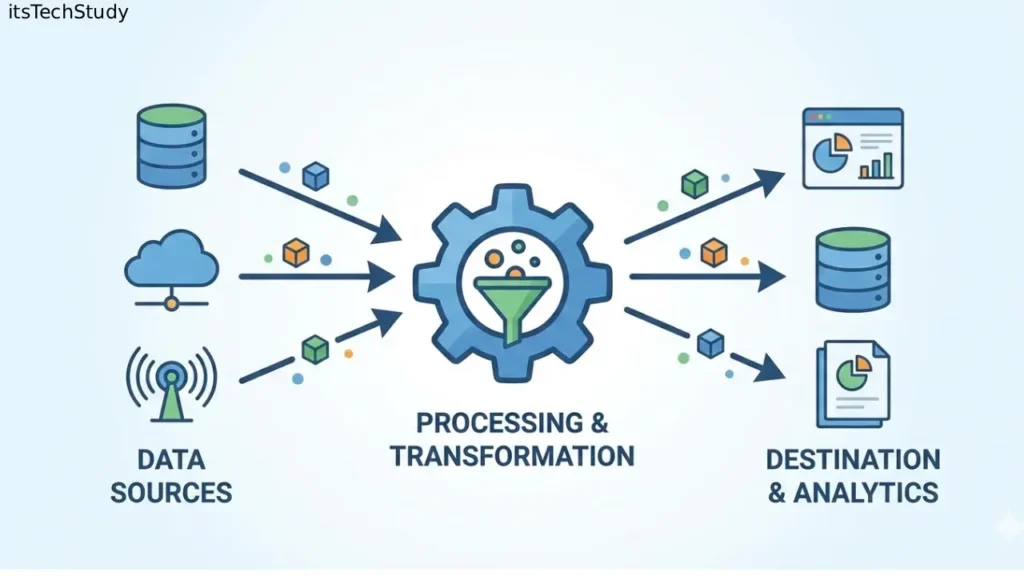
Data Pipeline Architecture (Step-by-Step)
A high-performing pipeline typically includes:
1. Data Sources
- APIs
- Databases
- CRM/ERP systems
- IoT devices
- Web apps
2. Ingestion Layer
Tools that capture data and route it:
- Apache Kafka
- AWS Kinesis
- Google Pub/Sub
- Azure Event Hubs
Storage Layer
Where the data sits:
- Data Lakes (raw data)
- Data Warehouses (structured data)
4. Processing & Transformation
- Apache Spark
- DBT
- Snowflake SQL
- Airflow tasks
5. Output / Consumption
Data goes to:
- BI Dashboards (Power BI, Tableau, Looker)
- Analytics models
- Machine learning workflows
- Applications and APIs
Pros & Cons of Data Pipelines
Pros
- Increases automation and efficiency
- Enables real-time analytics
- Prepares data for AI and ML use cases
- Improves decision-making accuracy
- Reduces human error and delays
Cons
- Requires technical skills to build & maintain
- Costs may rise with scale
- Complex security configuration
- Tool integration challenges
Popular Tools & Technologies for Data Pipelines
Best Ingestion Tools
- Apache Kafka
- AWS Glue
- Fivetran
Best Transformation Tools
- DBT
- Apache Spark
- Trifacta
Best Orchestration Tools
- Airflow
- Prefect
- Dagster
Best Storage Solutions
- Snowflake
- Google BigQuery
- AWS Redshift
- Azure Synapse
When Should Your Business Implement Data Pipelines?
You likely need a data pipeline if:
- You manage multiple data sources
- Reports take days instead of minutes
- Teams don’t trust current data
- Real-time decisions matter
- AI or analytics investment is planned
How to Build a Data Pipeline (Beginner Roadmap)
- Define your data goals
- Reporting? ML? Real-time dashboards?
- Identify data sources
- Make a complete list
- Choose pipeline type
- Batch, streaming, ETL, ELT
- Select tools
- Based on budget, volume, and skills
- Set validation & quality rules
- Standardize formatting, remove duplicates
- Secure data
- Encryption, access control, compliance
- Monitor & scale
- Continuous improvement is key
Best Practices for Scalable Data Pipelines
- Use modular architecture
- Prioritize data governance
- Monitor with alerts and dashboards
- Automate as much as possible
- Build for failure recovery
- Test with synthetic datasets first
Conclusion: The Future of Data Pipelines
Data pipelines are no longer optional – they’re the backbone of digital transformation. As AI, IoT, and real-time applications accelerate, businesses that invest in strong, automated, scalable pipelines will outperform competitors.
Whether you’re a startup or an enterprise, building pipelines today means preparing for tomorrow’s demands – faster, smarter, and more innovative operations.
Actionable Insight:
Start small, automate gradually, and focus on governance. Your data pipeline is not a project – it’s a long-term ecosystem.

About the Author
Tobias Hale is a technology writer and software analyst with a sharp eye on the ever-evolving world of digital innovation. With a deep passion for clean code, secure systems, and emerging technologies, Tobias brings clarity to complex topics - from the latest in operating system updates to cutting-edge software security practices.
FAQ: Data Pipelines (Common Questions Answered)
Q1: Are data pipelines the same as ETL?
Ans: Not exactly. ETL is one method within a pipeline. A pipeline can include ETL, streaming, analytics routing, and more.
Q2: Do I need coding skills to build a pipeline?
Ans: Basic coding helps, but low-code tools like Fivetran and Stitch make pipeline creation accessible to non-developers.
Q3: What is the difference between a data lake and a data warehouse?
Ans: Data Lake: Raw, unstructured data - flexible storage Data Warehouse: Clean, structured data - optimized for queries
Q4: How long does it take to build a pipeline?
Ans: Simple pipelines: 1–2 weeks Enterprise pipelines: 1–6 months depending on complexity
Q5: Is cloud better for data pipelines?
Ans: Yes - in 2025, cloud offers better scalability, cost efficiency, and integration features.







No Comments Yet
Be the first to share your thoughts.
Leave a Comment