

Introduction: Why Sequence Learning Still Matters in Modern AI
Before transformer models became the face of artificial intelligence, another family of neural networks quietly laid the foundation for many of the breakthroughs we now take for granted. If you have ever used voice typing, machine translation, predictive text, chatbot suggestions, stock forecasting tools, or time-series analysis systems, there is a strong chance that RNN, LSTM, or GRU architectures played a role somewhere in that evolution.
In the early days of deep learning, standard feedforward neural networks were excellent at recognizing patterns in fixed-size inputs like images or tabular data. But they struggled badly with sequential data—the kind of data where order matters. Language, speech, sensor streams, weather patterns, stock prices, and user behavior logs all have a timeline or dependency structure. The meaning of one data point often depends on what came before it. That is where Recurrent Neural Networks (RNNs) entered the scene.
RNNs were designed to “remember” previous inputs while processing new ones, making them ideal for sequential tasks. However, they came with limitations, especially when dealing with long sequences. This led to the development of LSTM (Long Short-Term Memory) networks, which improved memory handling and made sequence learning far more practical. Later, GRU (Gated Recurrent Unit) emerged as a lighter and often faster alternative that simplified the LSTM structure while preserving strong performance.
Today, even in the age of transformers, these models remain highly relevant. Why? Because they are often more lightweight, easier to deploy, less resource-intensive, and still very effective for many real-world applications-especially when working with limited data, edge devices, embedded AI, or classic time-series forecasting pipelines.
In this guide, we’ll break down GRU vs RNN vs LSTM in plain English, compare how they work, explore their strengths and weaknesses, and help you understand which neural network model is best for your machine learning project.
What Are RNN, LSTM, and GRU in Deep Learning?
At a high level, all three are types of recurrent neural networks used to process sequence data.
Sequence Data Examples
- Text and sentences
- Speech and audio streams
- Time-series data
- Stock market trends
- Sensor data from IoT devices
- Video frame sequences
- User activity logs
Unlike traditional neural networks, recurrent models pass information from one step to the next, creating a form of memory.
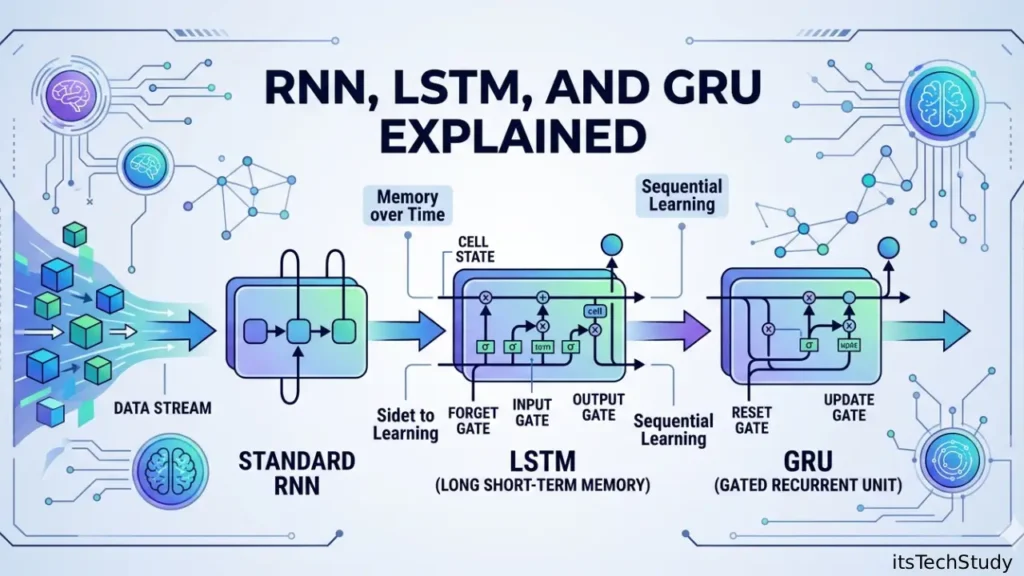
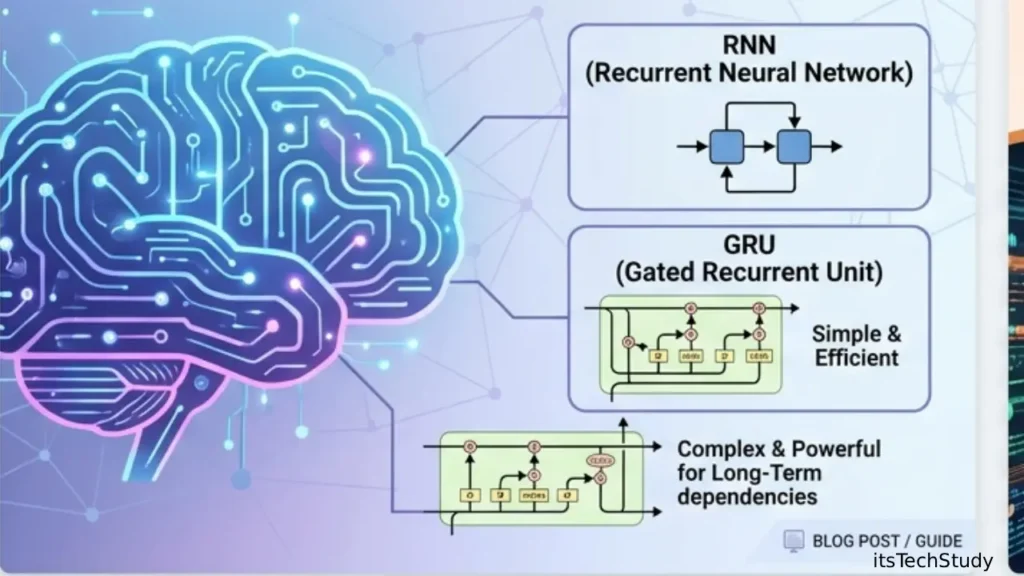
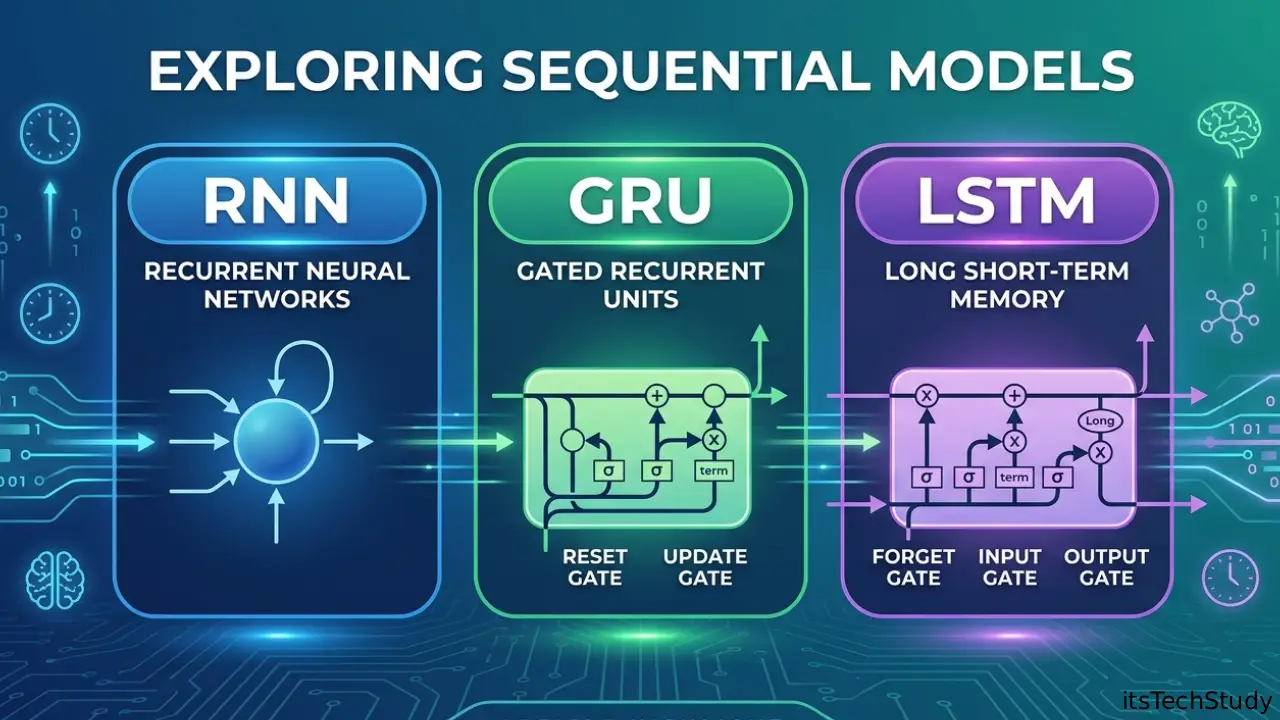
What Is an RNN (Recurrent Neural Network)?
A Recurrent Neural Network (RNN) is the basic architecture designed for sequential processing. It reads input one step at a time and keeps a hidden state, which acts like memory of previous inputs.
How RNN Works
For each time step:
- It takes the current input
- It combines it with the previous hidden state
- It produces a new hidden state
- It optionally generates an output
This makes RNNs suitable for tasks where context matters.
Common RNN Use Cases
- Text generation
- Language modeling
- Sentiment analysis
- Speech recognition
- Sequence labeling
- Time-series prediction
The Main Problem with Basic RNNs
RNNs struggle with long-term dependencies. When sequences become longer, the network can “forget” important earlier information. This happens because of the vanishing gradient problem, where gradients become too small during backpropagation.
For example, in a sentence like:
“The book that I bought last month from the old store was excellent.”
A simple RNN may struggle to remember that “book” is the subject when processing the word “excellent” much later.
What Is LSTM (Long Short-Term Memory)?
LSTM is a special type of RNN designed to solve the memory limitations of standard RNNs. It was introduced to better capture long-range dependencies in sequence data.
Instead of relying on a single hidden state, LSTM uses a more advanced memory system with cell state and gates.
Key Components of LSTM
An LSTM cell typically has:
- Forget Gate – decides what information to discard
- Input Gate – decides what new information to store
- Cell State – the long-term memory
- Output Gate – decides what to pass forward
This gating mechanism helps LSTM preserve important information over longer sequences.
Why LSTM Became Popular
LSTM was a major breakthrough because it allowed neural networks to:
- Learn from longer sequences
- Reduce vanishing gradient issues
- Improve language and time-series performance
- Handle more complex temporal patterns
Popular LSTM Applications
- Machine translation
- Speech-to-text systems
- Handwriting recognition
- Financial forecasting
- Demand prediction
- Music generation
- NLP sequence tasks
What Is GRU (Gated Recurrent Unit)?
GRU is a newer recurrent architecture introduced as a simpler alternative to LSTM. It keeps the benefits of gating but uses fewer gates and fewer parameters, making it computationally lighter.
Key Components of GRU
A GRU typically uses:
- Update Gate – controls how much past information to keep
- Reset Gate – controls how much past information to forget
Unlike LSTM, GRU does not have a separate cell state. It combines memory and hidden state into a single representation.
Why GRU Is Popular
GRUs often:
- Train faster than LSTMs
- Require less memory
- Perform similarly on many tasks
- Work well on smaller datasets
- Fit edge AI and lightweight deployments
Common GRU Use Cases
- Real-time prediction systems
- Chatbots
- IoT analytics
- Time-series forecasting
- Sequence classification
- Lightweight NLP models
RNN vs LSTM vs GRU: Core Differences at a Glance
Below is a practical comparison of the three models.
Comparison Table: RNN vs LSTM vs GRU
| Feature | RNN | LSTM | GRU |
|---|---|---|---|
| Full Form | Recurrent Neural Network | Long Short-Term Memory | Gated Recurrent Unit |
| Handles Short Sequences | Yes | Yes | Yes |
| Handles Long-Term Dependencies | Weak | Strong | Strong |
| Vanishing Gradient Resistance | Poor | Good | Good |
| Complexity | Low | High | Medium |
| Training Speed | Fastest (simple structure) | Slower | Faster than LSTM |
| Number of Parameters | Lowest | Highest | Lower than LSTM |
| Memory Efficiency | High | Lower | Better than LSTM |
| Accuracy on Complex Sequences | Limited | Excellent | Very Good to Excellent |
| Best For | Simple sequence tasks | Long and complex dependencies | Efficient sequence learning |
How RNN, LSTM, and GRU Actually Differ in Practice
The theory is useful, but in real-world machine learning projects, the choice often comes down to a few practical questions.
1. How Long Is Your Sequence?
- Short sequence? Basic RNN may be enough.
- Long sequence? LSTM or GRU is usually better.
2. How Much Compute Do You Have?
- Limited GPU/CPU resources? GRU is often a smart compromise.
- High compute and need best long-context learning? LSTM is a strong choice.
3. Is Model Simplicity Important?
- RNN is easiest to understand
- GRU is simpler than LSTM
- LSTM is the most complex but often most expressive
4. Are You Working on Edge Devices or Embedded Systems?
- GRU often wins because it is lighter and faster
- RNN can also be useful for extremely simple tasks
- LSTM may be too heavy in constrained environments
Pros and Cons of RNN
Pros of RNN
- Simple architecture
- Easier to implement and understand
- Good for short sequence dependencies
- Lower parameter count
- Useful in educational and baseline experiments
Cons of RNN
- Suffers from vanishing gradients
- Poor at learning long-term dependencies
- Unstable for long sequences
- Lower performance on complex NLP and forecasting tasks
- Often outperformed by LSTM and GRU
Pros and Cons of LSTM
Pros of LSTM
- Excellent at capturing long-term dependencies
- Strong performance on complex sequence tasks
- More stable training than basic RNN
- Great for language modeling and long time-series
- Proven architecture in many production systems
Cons of LSTM
- More parameters
- Slower training
- Higher memory usage
- More complex to tune
- Can be overkill for small or simple datasets
Pros and Cons of GRU
Pros of GRU
- Faster than LSTM in many cases
- Fewer parameters than LSTM
- Good balance between performance and efficiency
- Often works well with smaller datasets
- Easier to deploy in lightweight systems
Cons of GRU
- Slightly less expressive than LSTM in some long-sequence tasks
- Can underperform LSTM in highly complex dependency structures
- Still more complex than a basic RNN
- Less interpretable than simpler recurrent setups
When Should You Use RNN, LSTM, or GRU?
Choosing the right model depends on your project goals, data size, and hardware constraints.
Best Use Cases by Model
Use RNN When:
- You need a simple baseline model
- Your sequences are short
- You are teaching or learning sequence modeling
- The task is computationally minimal
- Long-term context is not important
Use LSTM When:
- Your data has long-range dependencies
- You are working on complex NLP tasks
- You need stronger memory retention
- Accuracy matters more than speed
- You are forecasting over longer time windows
Use GRU When:
- You want near-LSTM performance with lower cost
- Training speed matters
- You need a lightweight deep learning model
- You are deploying on limited hardware
- You want a strong default choice for many sequence tasks
RNN, LSTM, and GRU in Natural Language Processing (NLP)
Before transformers dominated NLP, recurrent architectures were everywhere.
How They Help in NLP
- Predict next words in a sentence
- Understand sentiment across a sequence
- Translate languages
- Tag parts of speech
- Detect named entities
- Generate text sequences
Practical NLP Insight
- RNN: Works for very basic text tasks or short text classification
- LSTM: Better for longer documents and contextual understanding
- GRU: Great balance for fast and practical NLP pipelines
Even now, many lightweight NLP systems still use GRU or LSTM when transformers are too expensive.
RNN, LSTM, and GRU in Time-Series Forecasting
These models are also widely used in time-series forecasting, especially in business and engineering.
Popular Time-Series Applications
- Sales forecasting
- Energy consumption prediction
- Weather modeling
- Stock trend analysis
- Traffic prediction
- Sensor anomaly detection
Why Recurrent Models Work Well
They can learn:
- Trend continuity
- Seasonality patterns
- Temporal correlations
- Lagged relationships
- Event-driven sequence shifts
For most real-world forecasting pipelines:
- LSTM is often chosen for complex long windows
- GRU is preferred when speed matters
- RNN is mainly used as a benchmark or for simple series
RNN vs LSTM vs GRU for Beginners: Which One Should You Learn First?
If you are new to deep learning, the smartest path is:
- Start with RNN to understand the concept of recurrence
- Move to LSTM to understand gating and memory
- Learn GRU as the efficient modern recurrent alternative
This learning order makes the architecture differences much easier to grasp.
Recommended Learning Path
- Learn sequence data basics
- Understand hidden states
- Study vanishing gradients
- Implement simple RNN in TensorFlow or PyTorch
- Build an LSTM sentiment model
- Compare it with a GRU version
- Benchmark speed and accuracy
Are LSTM and GRU Still Relevant in the Transformer Era?
This is one of the most common modern questions.
Short Answer: Yes, Absolutely
Transformers are powerful, but they are not always the best option.
Why Recurrent Models Still Matter
- Lower computational cost
- Faster inference in smaller environments
- Better for streaming/online sequential input in some cases
- Useful for embedded and edge AI
- Easier to train on smaller datasets
- Less resource-hungry than transformer stacks
Where They Still Shine
- Industrial IoT
- Small business forecasting tools
- Mobile AI applications
- On-device analytics
- Low-latency sequence prediction
- Legacy production systems
For many practical tech projects, GRU and LSTM remain highly useful and cost-effective.
Common Mistakes When Choosing Between RNN, LSTM, and GRU
Many beginners choose the wrong architecture for the wrong reason.
Avoid These Mistakes
- Using basic RNN for long text or long sequences
- Assuming LSTM is always best without testing GRU
- Ignoring training time and hardware constraints
- Not normalizing time-series data properly
- Using too few sequence steps
- Overfitting with overly deep recurrent layers
- Skipping validation on sequence length sensitivity
Smart Tip
If you are unsure, start with GRU as a strong baseline, then compare against LSTM if the task is complex.
Quick Decision Guide: Which Model Should You Pick?
Choose RNN if you need:
- Simplicity
- Educational understanding
- Fast prototyping
- Very short sequence handling
Choose LSTM if you need:
- Long memory
- Strong performance on complex sequences
- Robust NLP or long forecasting
- Richer temporal modeling
Choose GRU if you need:
- Efficiency
- Strong performance with fewer parameters
- Faster training
- A practical production-friendly recurrent model
Conclusion: RNN, LSTM, or GRU-What’s the Smartest Choice Today?
RNN, LSTM, and GRU represent an important chapter in the evolution of deep learning, and they are still highly relevant for many modern AI applications. RNNs introduced the idea of sequence memory but struggle with long-term context. LSTMs solved many of those issues with a powerful gated memory system, making them a long-time favorite for complex sequence tasks. GRUs streamlined that idea into a lighter, faster, and often equally effective architecture.
If you are building a modern project and want a practical rule of thumb:
- Use RNN for learning or simple baselines
- Use LSTM for complex long-sequence tasks
- Use GRU when you want strong performance with better efficiency
In a world obsessed with giant transformer models, these recurrent networks still offer something valuable: focused, efficient, and accessible sequence intelligence. For developers, students, and tech teams working on forecasting, NLP, edge AI, or resource-sensitive systems, understanding GRU vs RNN vs LSTM is still one of the smartest investments you can make.

About the Author
Amelia Morgan is a Editor at itsTechStudy.com with 15+ years of experience in the technology industry. I write about emerging innovations, AI, and digital trends-making complex topics simple and engaging for readers.
FAQ: GRU, RNN, and LSTM
Q1: What is the main difference between RNN, LSTM, and GRU?
Ans: The main difference is how they handle memory in sequential data. A basic RNN has a simple hidden state and struggles with long-term dependencies. LSTM adds multiple gates and a cell state to better preserve information over long sequences. GRU simplifies LSTM with fewer gates, making it faster and lighter while still handling long dependencies well.
Q2: Which is better: GRU or LSTM?
Ans: There is no universal winner. LSTM is often better for very complex sequence tasks with long-term dependencies, while GRU is usually faster, more memory-efficient, and can achieve similar performance on many practical tasks. If you want a balanced starting point, GRU is often the better first choice.
Q3: Why do basic RNNs suffer from vanishing gradients?
Ans: During backpropagation through time, the gradient is repeatedly multiplied across many time steps. When those values become very small, the model cannot effectively learn from earlier inputs. This is called the vanishing gradient problem, and it makes standard RNNs weak at remembering long-range context.
Q4: Is GRU faster than LSTM?
Ans: Yes, in many cases GRU is faster than LSTM because it has fewer gates and fewer parameters. That means reduced computational overhead, faster training, and lower memory usage. However, actual performance depends on dataset size, framework optimization, and model tuning.
Q5: Are LSTM and GRU outdated because of transformers?
Ans: No. While transformers dominate large-scale NLP and generative AI, LSTM and GRU are still relevant for lightweight applications, time-series forecasting, edge AI, streaming data, and projects with limited compute. They remain practical and cost-effective in many production environments.
Q6: Which model should beginners learn first for deep learning?
Ans: Beginners should usually learn in this order: RNN to understand recurrence LSTM to understand gating and memory GRU to understand efficient recurrent design This progression makes the concepts easier to understand and helps build a stronger foundation in sequence modeling.







No Comments Yet
Be the first to share your thoughts.
Leave a Comment