


Introduction: Why Modern Software Can’t Afford to Be Slow
A decade ago, many applications could get away with being a little sluggish. Websites loaded a bit slower, APIs weren’t hit millions of times per minute, and users were more forgiving. But today’s digital world is very different. Whether it’s a social media feed, an e-commerce platform, a streaming service, or a SaaS dashboard, users expect near-instant responses. If an app feels slow, they leave. If a backend struggles under load, costs rise and reliability drops.
That’s where caching becomes one of the most important performance tools in software engineering.
Instead of repeatedly fetching the same data from a slow database, API, or disk, applications use a cache to store frequently accessed information in faster memory. But there’s a catch: memory is limited. You can’t keep everything forever. So when the cache gets full, the system must decide what to remove.
This is exactly the problem that the LRU Cache solves.
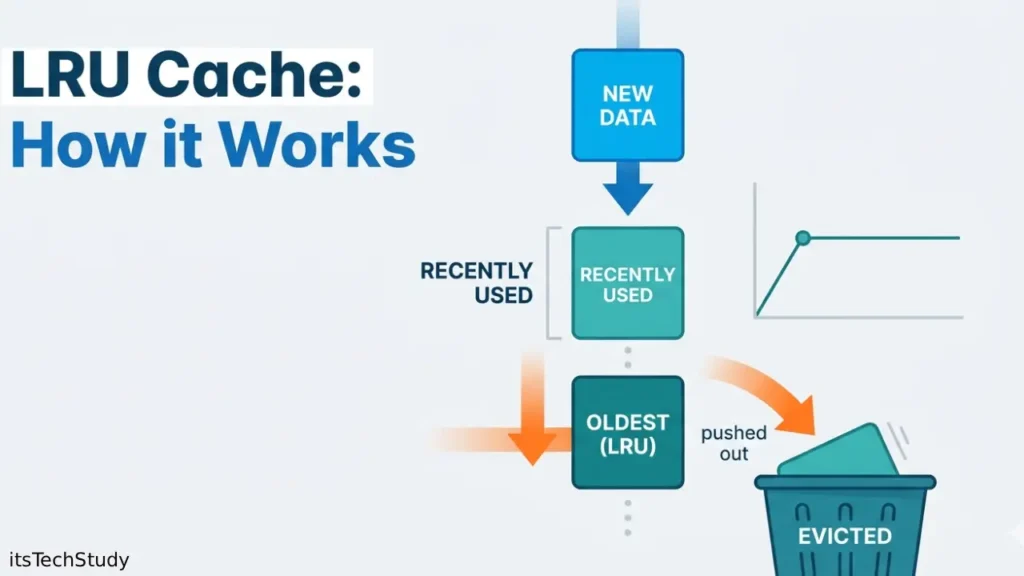
LRU Cache, short for Least Recently Used Cache, is one of the most widely used cache eviction policies in computer science and system design. Its logic is elegant and practical: when the cache is full, remove the item that hasn’t been used for the longest time. In many real-world applications, recently used data is more likely to be used again soon, making LRU a highly effective strategy.
In this guide, we’ll break down what an LRU Cache is, how it works, why it matters in modern systems, where it shines, where it falls short, and how developers implement it in production-grade software. If you’ve heard about cache replacement algorithms, system design cache strategies, or backend performance optimization, this is one concept you absolutely need to understand.
What Is an LRU Cache?
An LRU Cache (Least Recently Used Cache) is a fixed-size cache that stores a limited number of items and automatically removes the least recently accessed item when it needs space for a new one.
In simple terms:
- The cache has a capacity (for example, 3 items).
- When you access or add an item, it becomes recently used.
- If the cache is full and a new item needs to be added, the oldest unused item gets removed.
A Simple Example
Imagine a cache that can hold 3 items:
- Add A ->
[A] - Add B ->
[A, B] - Add C ->
[A, B, C] - Access A -> A becomes most recently used ->
[B, C, A] - Add D -> Cache is full, remove B (least recently used) ->
[C, A, D]
This behavior makes LRU a natural fit for systems where recent access patterns are a strong predictor of future access.
Why LRU Cache Matters in Modern Software Systems
In real applications, speed is often a competitive advantage. Databases, APIs, and file systems are much slower than RAM. Every time you avoid a slow fetch by serving data from memory, you reduce latency and improve the user experience.
Common reasons developers use LRU Cache:
- Reduce database load
- Lower API response times
- Improve application scalability
- Save compute resources
- Boost user-perceived performance
Real-world use cases include:
- Browser caching
- CDN edge content caching
- Database query result caching
- Session and token storage
- Machine learning feature caching
- Microservices response caching
- DNS lookup caching
- Page rendering optimization
In many backend systems, an in-memory cache with an LRU eviction policy is one of the first optimizations engineers reach for when performance becomes a bottleneck.
How the LRU Cache Algorithm Works
At its core, the LRU cache algorithm supports two primary operations:
- GET(key) -> Return the value if it exists in cache
- PUT(key, value) -> Insert or update the value
To be efficient, both operations should ideally work in O(1) time complexity.
The classic implementation uses:
- A Hash Map (Dictionary) for fast key lookup
- A Doubly Linked List for tracking usage order
Why this combination?
Hash Map
The hash map lets you quickly find whether a key exists in the cache.
Doubly Linked List
The linked list keeps track of usage order:
- Head = Most recently used item
- Tail = Least recently used item
Whenever an item is accessed:
- Move it to the front (head)
Whenever the cache is full:
- Remove the tail
This structure makes LRU efficient and practical even under heavy workloads.
LRU Cache Data Structure Breakdown
Here’s how the internal logic usually works:
On GET(key):
- Check if the key exists in the hash map
- If not found, return a cache miss (often
-1or null) - If found:
- Move the node to the front of the linked list
- Return the value
On PUT(key, value):
- If the key already exists:
- Update its value
- Move it to the front
- If the key does not exist:
- If the cache is full:
- Remove the least recently used item (tail)
- Delete it from the hash map
- Insert the new item at the front
- Add it to the hash map
- If the cache is full:
This is why LRU cache implementation is a popular interview question-it tests both data structure knowledge and performance reasoning.
LRU Cache vs Other Cache Eviction Policies
Not all caches behave the same. Different workloads require different strategies. LRU is popular, but it’s not always the perfect choice.
Comparison Table: LRU vs Other Cache Eviction Policies
| Policy | Full Form | Eviction Logic | Best Use Case | Strength | Weakness |
|---|---|---|---|---|---|
| LRU | Least Recently Used | Remove oldest recently unused item | General-purpose apps, web services | Great for recency-based access patterns | Can fail on sequential scans |
| FIFO | First In, First Out | Remove oldest inserted item | Simple systems | Easy to implement | Ignores access frequency and recency |
| LFU | Least Frequently Used | Remove least accessed item | Stable hot datasets | Good when frequent items stay important | More complex and slower to manage |
| MRU | Most Recently Used | Remove newest accessed item | Rare niche workloads | Useful in some scan-heavy patterns | Poor fit for most apps |
| Random Replacement | Random item eviction | Remove a random item | Low-overhead environments | Very simple | Unpredictable performance |
For many applications, LRU Cache hits the sweet spot between simplicity, performance, and practical accuracy.
Advantages of LRU Cache
LRU has remained popular for a reason. It aligns well with how many real-world systems behave.
Pros of Using LRU Cache
- Easy to understand and reason about
The eviction rule is intuitive and maps well to actual usage patterns. - Works well in many real-world workloads
If users or systems tend to revisit recently accessed data, LRU performs very well. - Fast operations with the right data structures
With a hash map + doubly linked list, GET and PUT can be O(1). - Excellent for backend performance optimization
It can dramatically reduce repeated reads from databases or remote services. - Widely supported in frameworks and libraries
Many languages offer built-in or standard LRU-like utilities.
Limitations of LRU Cache
As useful as it is, LRU isn’t perfect. Like any cache replacement algorithm, it can struggle when the workload doesn’t match its assumptions.
Cons of Using LRU Cache
- Poor performance on scan-heavy workloads
If the system reads many unique items in sequence, LRU may evict useful entries too aggressively. - Recency isn’t always the best signal
Sometimes frequency matters more than recent access. - Implementation complexity is moderate
A proper O(1) version is more involved than basic queues or arrays. - Memory overhead
The linked list pointers and hash map entries add some overhead. - Can thrash under certain patterns
Repeated large working sets bigger than cache capacity can reduce effectiveness.
When Should You Use an LRU Cache?
An LRU cache is most effective when recent access strongly predicts future access.
Use LRU Cache when:
- Your application repeatedly accesses recently requested data
- You need a fast in-memory cache
- You want a proven and balanced cache eviction policy
- Your dataset is larger than available memory
- You need predictable, low-latency cache operations
Great use cases for LRU:
- API response caching
- User profile caching
- Database query result caching
- Template rendering caches
- CDN object caching (in some layers)
- Search result caching
- Configuration and metadata caching
When LRU Cache May Not Be the Best Choice
There are situations where LRU underperforms.
Consider alternatives when:
- Access patterns are frequency-heavy rather than recency-heavy
- Your workload involves large sequential scans
- You need smarter admission policies
- Your cache must adapt to multiple workload shapes
Better alternatives in some cases:
- LFU for highly repetitive hot items
- ARC for adaptive behavior
- TinyLFU / W-TinyLFU for modern high-performance caching systems
- FIFO when simplicity matters more than optimization
If you’re building high-scale systems, choosing the right cache eviction strategy can have a major impact on both performance and infrastructure cost.
Step-by-Step Example of LRU Cache in Action
Let’s make the concept concrete with a small scenario.
Cache capacity = 3
Operations:
PUT(1, A)→ Cache:[1]PUT(2, B)→ Cache:[1, 2]PUT(3, C)→ Cache:[1, 2, 3]GET(1)→ Cache:[2, 3, 1]PUT(4, D)→ Evict2→ Cache:[3, 1, 4]GET(3)→ Cache:[1, 4, 3]PUT(5, E)→ Evict1→ Cache:[4, 3, 5]
What happened?
- Items
2and1were removed because they were the least recently used - Even though they were inserted earlier, what mattered most was recent access
This is the heart of the least recently used cache concept.
LRU Cache in System Design Interviews
If you’re preparing for software engineering interviews, especially backend or system design roles, LRU Cache is a must-know topic.
Why interviewers love LRU Cache:
- It tests understanding of data structures
- It checks time complexity awareness
- It reveals whether you can balance correctness and performance
- It mirrors real-world system design cache problems
What interviewers often expect:
- O(1)
GET - O(1)
PUT - Hash map + doubly linked list approach
- Clean handling of updates and evictions
- Ability to explain trade-offs
If you can confidently explain why a linked list alone is too slow, and why the hash map + doubly linked list combination works, you’re already ahead of many candidates.
Practical Implementation Tips for Developers
Whether you’re coding in Python, Java, JavaScript, C++, or Go, the core logic remains the same.
Best practices for LRU cache implementation:
- Define cache capacity clearly
Don’t let it grow unbounded. - Track both key and value in each node
You’ll need the key when evicting from the tail. - Use dummy head and tail nodes
This simplifies insert/remove operations in a doubly linked list. - Handle updates carefully
Existing keys should move to the front after updates. - Think about thread safety
In concurrent environments, add locking or use a thread-safe cache library. - Measure hit ratio
Don’t assume the cache is helping—monitor cache hit rate, misses, and evictions. - Tune capacity based on workload
Too small = constant eviction. Too large = wasted memory.
Common Mistakes Developers Make with LRU Cache
Even experienced developers sometimes misuse caching.
Avoid these pitfalls:
- Using LRU without understanding access patterns
- Ignoring cache invalidation strategy
- Caching stale or highly volatile data
- Choosing capacity arbitrarily
- Not measuring hit/miss ratios
- Assuming cache = guaranteed speedup
- Forgetting memory overhead in production
Remember: a cache is only useful if it improves the ratio of fast hits to slow misses.
LRU Cache and Performance Optimization
When used correctly, LRU can make a noticeable difference.
Key performance benefits:
- Lower average response time
- Reduced database or API calls
- Better throughput under traffic spikes
- Improved scalability
- Lower infrastructure pressure
But performance depends on:
- Cache size
- Access distribution
- Data volatility
- Read/write ratio
- Eviction churn
- Serialization/deserialization overhead
In other words, LRU Cache is not magic. It’s a strong optimization tool—but only when aligned with actual workload behavior.
Conclusion: Why LRU Cache Still Matters
The LRU Cache remains one of the most important and practical concepts in modern software engineering—and for good reason. It solves a universal problem: how to keep fast-access memory useful when space is limited. By removing the least recently used item first, it mirrors how many real systems behave and delivers strong performance in a wide range of applications.
If you’re a developer, architect, or tech enthusiast, understanding LRU cache algorithms, cache eviction policies, and in-memory caching strategies will make you better at building fast, scalable systems. And if you’re preparing for interviews, mastering the LRU Cache is almost non-negotiable.
The best next step? Don’t just memorize the concept-implement it yourself, test it under different access patterns, and measure the hit rate. That’s where the real learning happens. In modern tech, speed matters, and a well-designed cache is often the difference between a system that struggles and one that scales gracefully.

About the Author
Amelia Morgan is a Editor at itsTechStudy.com with 15+ years of experience in the technology industry. I write about emerging innovations, AI, and digital trends-making complex topics simple and engaging for readers.
FAQ: LRU Cache Explained
Q1: What does LRU stand for in LRU Cache?
Ans: LRU stands for Least Recently Used. It means that when the cache is full, the item that hasn’t been accessed for the longest time is removed first. This makes it a popular cache eviction policy in software systems.
Q2: Why is LRU Cache so popular in system design?
Ans: LRU Cache is popular because it is: Easy to understand Efficient with O(1) operations when implemented correctly Practical for many real-world workloads Widely applicable in APIs, databases, browsers, and backend systems It offers a strong balance between simplicity and performance.
Q3: What data structures are used to implement an LRU Cache?
Ans: The most common and efficient implementation uses: A Hash Map for fast key lookup A Doubly Linked List for tracking recency order This allows both GET and PUT operations to run in constant time.
Q4: What is the difference between LRU and LFU cache?
Ans: The main difference is: LRU removes the item that was used least recently LFU removes the item that has been used the fewest times LRU focuses on recency, while LFU focuses on frequency. LRU is generally simpler and often better for short-term access patterns, while LFU can be stronger when hot items remain popular for a long time.
Q5: Is LRU Cache always the best choice?
Ans: No. LRU works very well for many applications, but it is not universal. It may perform poorly in: Sequential scan workloads Large streaming data access Workloads where frequency matters more than recency In those cases, alternatives like LFU or TinyLFU may perform better.
Q6: Where is LRU Cache used in real life?
Ans: You’ll find LRU-like caching behavior in many systems, including: Web browsers Backend APIs Database query layers Microservices In-memory application caches Content delivery systems DNS resolvers It’s one of the most practical and widely recognized caching in computer science concepts.






No Comments Yet
Be the first to share your thoughts.
Leave a Comment