

Why This Matters Right Now
A few years ago, most systems pushed data straight to the cloud.
Now? Devices are smarter, factories need instant alerts, stores want local analytics, and remote sites cannot depend on stable internet. That means edge computing is no longer optional. Data must be processed closer to where it is created.
This is where many teams hit a wall:
Should we use MQTT or Kafka at the edge?
It sounds like a simple tool comparison. It isn’t.
I’ve seen teams deploy Kafka on tiny gateways that barely had enough RAM to breathe. I’ve also seen teams use MQTT for workloads that needed durable replay and analytics pipelines. Both choices created avoidable pain.
If you’re building IoT, industrial automation, smart retail, vehicle telemetry, or remote monitoring systems, choosing the wrong messaging layer can cost months of rework.
Let’s fix that.
Quick Summary Box
Use MQTT when devices need lightweight, reliable communication over weak networks.
Use Kafka when you need high-volume streaming, retention, replay, and analytics.
Use both when devices talk locally via MQTT and business systems consume data via Kafka.
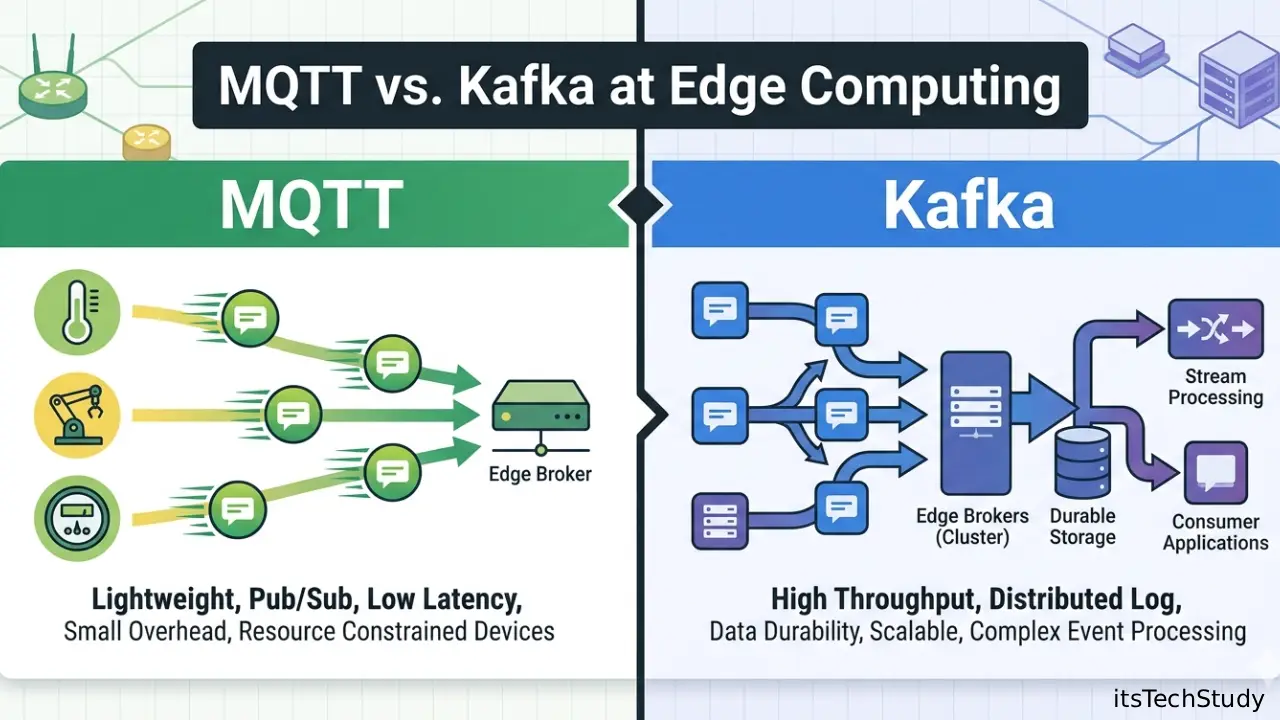
What Are MQTT and Kafka at Edge?
MQTT in Simple Terms
MQTT is a lightweight publish-subscribe messaging protocol built for constrained devices and unreliable networks.
Think:
- Sensors
- Cameras
- PLCs
- Smart meters
- Mobile or remote devices
It is excellent when bandwidth is limited.
Kafka in Simple Terms
Kafka is a distributed event streaming platform designed for high-throughput data pipelines.
Think:
- Millions of events per day
- Stream processing
- Historical replay
- Multiple consumers reading same data
- Analytics pipelines
Kafka shines when data becomes a product, not just a message.
Real-World Experience: Where Beginners Usually Misjudge This
When I first worked on an edge telemetry design, the team assumed Kafka was automatically “better” because it sounded enterprise-grade.
We placed Kafka on a modest industrial gateway:
- 4 CPU cores
- 8 GB RAM
- SSD storage
It worked during testing.
Then production started. Logs grew. Topics multiplied. Consumer lag appeared. Disk usage became a constant maintenance issue.
We replaced the device-side layer with MQTT and moved Kafka upstream. Stability improved almost immediately.
Lesson: Best technology in the data center may be the wrong technology on a small edge box.
MQTT vs Kafka at Edge: Side-by-Side Comparison
| Feature | MQTT | Kafka |
|---|---|---|
| Best for | Device messaging | Event streaming |
| Network efficiency | Excellent | Moderate |
| Resource usage | Low | Higher |
| Offline tolerance | Good with sessions | Strong with retention |
| Replay old data | Limited | Excellent |
| Millions of messages/day | Good | Excellent |
| Easy on small gateways | Yes | Depends on hardware |
| Multi-consumer analytics | Basic | Excellent |
| Typical edge use | Sensors, commands | Local analytics hub |
When MQTT Is the Better Choice
1. Weak or Expensive Networks
If your devices run on 4G, satellite, rural broadband, or unstable Wi-Fi, MQTT usually wins.
Why?
- Tiny packet overhead
- Persistent sessions
- QoS levels
- Lower bandwidth cost
For remote farms or mining sites, this matters more than benchmark numbers.
2. Battery-Powered Devices
MQTT reduces chatter and connection cost.
For battery sensors sending data every 10 minutes, that can mean months of extra life.
3. Command and Control Systems
Need to turn a pump on, unlock a gate, or send firmware commands?
MQTT topics make this clean and fast.
When Kafka Is the Better Choice
1. Multiple Systems Need the Same Data
Suppose one machine emits temperature data.
And now:
- Dashboard needs it
- Alerting engine needs it
- AI model needs it
- Data lake needs it
Kafka handles this naturally because many consumers can read independently.
2. You Need Replay
One of Kafka’s biggest advantages:
If analytics fails today, you can replay yesterday’s stream.
That saves teams constantly.
3. Heavy Local Processing at Edge
In smart factories or retail stores, edge servers may run:
- Video metadata pipelines
- Fraud detection
- Demand forecasting
- Real-time dashboards
Kafka can become the local event backbone.
Mini Case Study: Smart Retail Store Deployment
A retailer wanted real-time inventory updates from 150 stores.
Each store had:
- Barcode scanners
- Shelf sensors
- POS systems
- Cameras
First Attempt
Everything sent directly to cloud Kafka.
Problems:
- Internet outages stopped updates
- Latency during peak hours
- Too much chatter from sensors
Better Architecture
At each store:
- Devices used MQTT locally
- Edge gateway filtered and aggregated events
- Gateway forwarded meaningful events to Kafka in cloud
Result:
- Lower bandwidth usage
- Better resilience
- Faster local actions
This hybrid model is more common than many beginners realize.
Step-by-Step Guide: How to Choose MQTT vs Kafka at Edge
Step 1: Count Your Devices
Under 500 lightweight devices? MQTT is often enough.
Thousands of events/sec with multiple apps consuming data? Kafka deserves consideration.
Step 2: Check Hardware Limits
If your gateway has:
- 2–4 GB RAM
- Modest CPU
- Small SSD
Be cautious with Kafka.
MQTT brokers usually fit easier.
Step 3: Ask If Replay Matters
Need to reprocess yesterday’s data?
Choose Kafka or add another storage layer.
Step 4: Measure Network Reality
Do not assume stable internet.
One mistake I made early on was designing for office Wi-Fi conditions while field sites had frequent drops.
MQTT handled that better.
Step 5: Decide If You Need Both
Often the smartest answer is not either/or.
Use:
- MQTT for device communication
- Kafka for enterprise streaming
Common Mistakes to Avoid
1. Installing Kafka on Tiny Devices
Kafka is powerful, but it expects resources.
Trying to run it on underpowered hardware often creates hidden operational cost.
2. Using MQTT as Long-Term Event Storage
MQTT brokers move messages well. They are not always ideal historical event stores.
3. Ignoring Topic Design
Bad naming becomes chaos later.
Use structured topics like:
factory1/line2/motor7/temp
4. Sending Raw Sensor Noise
Many sensors emit noisy data every second.
Filter or aggregate at edge first.
This alone can reduce bandwidth by 70%+ in some environments.
5. No Offline Plan
What happens when internet dies for 6 hours?
If you cannot answer that, architecture is incomplete.
Pros and Cons
MQTT Pros
- Lightweight
- Fast on poor networks
- Easy for devices
- Low resource usage
- Great for commands
MQTT Cons
- Limited replay/history
- Less ideal for complex analytics fan-out
- Governance can become messy at scale
Kafka Pros
- Strong durability
- Replayable streams
- Excellent for multiple consumers
- Great analytics backbone
- High throughput
Kafka Cons
- Heavier operations burden
- More storage planning required
- Not ideal for tiny gateways
- Overkill for simple device fleets
Pro Tips (Advanced but Practical)
1. Use MQTT Retained Messages Carefully
Retained state is useful for device status.
But stale retained messages can confuse systems after device replacement.
Many beginners miss this.
2. Aggregate Before Kafka
Instead of sending every vibration reading, send:
- min
- max
- average
- anomalies
Huge savings.
3. Use Kafka at Regional Edge, Not Micro Edge
A non-obvious strategy:
Run MQTT on device gateways, Kafka on regional nodes (warehouse, plant server, branch data room).
This balances cost and power.
4. Watch Storage Writes
Kafka can stress SSDs with sustained writes. On rugged edge hardware, disk wear matters more than most articles mention.
5. Security Operations Matter More Than Benchmarks
TLS certificates, auth rotation, access control, remote updates—these often matter more than message throughput.
Unique Insights Most Articles Miss
- Disk endurance can decide Kafka viability at edge more than CPU.
- MQTT topic sprawl becomes a governance issue before performance becomes a problem.
- Many “Kafka at edge” deployments are actually regional edge, not true device edge.
- Filtering noisy sensor data before forwarding often gives bigger gains than changing protocols.
- Operational simplicity usually beats theoretical scalability in remote locations.
- A stable MQTT + cloud Kafka system often outperforms poorly managed local Kafka.
Key Takeaway Box
If your main challenge is devices, start with MQTT.
If your main challenge is data pipelines, start with Kafka.
If your challenge is both, build a bridge between them.
Final Verdict: My Honest Opinion
Too many teams treat MQTT vs Kafka at edge like a winner-takes-all battle.
That mindset causes bad architecture.
In my experience:
- MQTT wins the last mile to devices
- Kafka wins the broader event ecosystem
If you are a beginner, don’t start by asking which tool is more powerful.
Ask:
- Where is the data created?
- How unreliable is the network?
- Who needs the data later?
- How much maintenance can we realistically handle?
Those questions lead to better systems than any benchmark chart.
If I were starting today, I’d choose MQTT first for device connectivity, then introduce Kafka only when replay, analytics, or multi-team consumption becomes real.
That approach saves money, complexity, and regret.

About the Author
Amelia Morgan is a Editor at itsTechStudy.com with 15+ years of experience in the technology industry. I write about emerging innovations, AI, and digital trends-making complex topics simple and engaging for readers.
FAQ: MQTT vs Kafka at Edge
Q1: Is MQTT faster than Kafka?
Ans: For lightweight device messaging over unstable networks, often yes in practical terms. Kafka may win on throughput in data-center style workloads.
Q2: Can Kafka replace MQTT completely?
Ans: Sometimes, but usually not efficiently for constrained devices.
Q3: Can I use both MQTT and Kafka together?
Ans: Yes. This is often the best architecture.
Q4: Is Kafka too heavy for Raspberry Pi style hardware?
Ans: Usually for serious production workloads, yes. Small demos are different from real operations.
Q5: Does MQTT store messages forever?
Ans: Typically no. It depends on broker setup and persistence features.
Q6: Which is easier for beginners?
Ans: MQTT is easier to start with. Kafka has a steeper operational learning curve.
Q7: Which is cheaper?
Ans: For simple edge fleets, MQTT often costs less in infrastructure and maintenance.






No Comments Yet
Be the first to share your thoughts.
Leave a Comment