

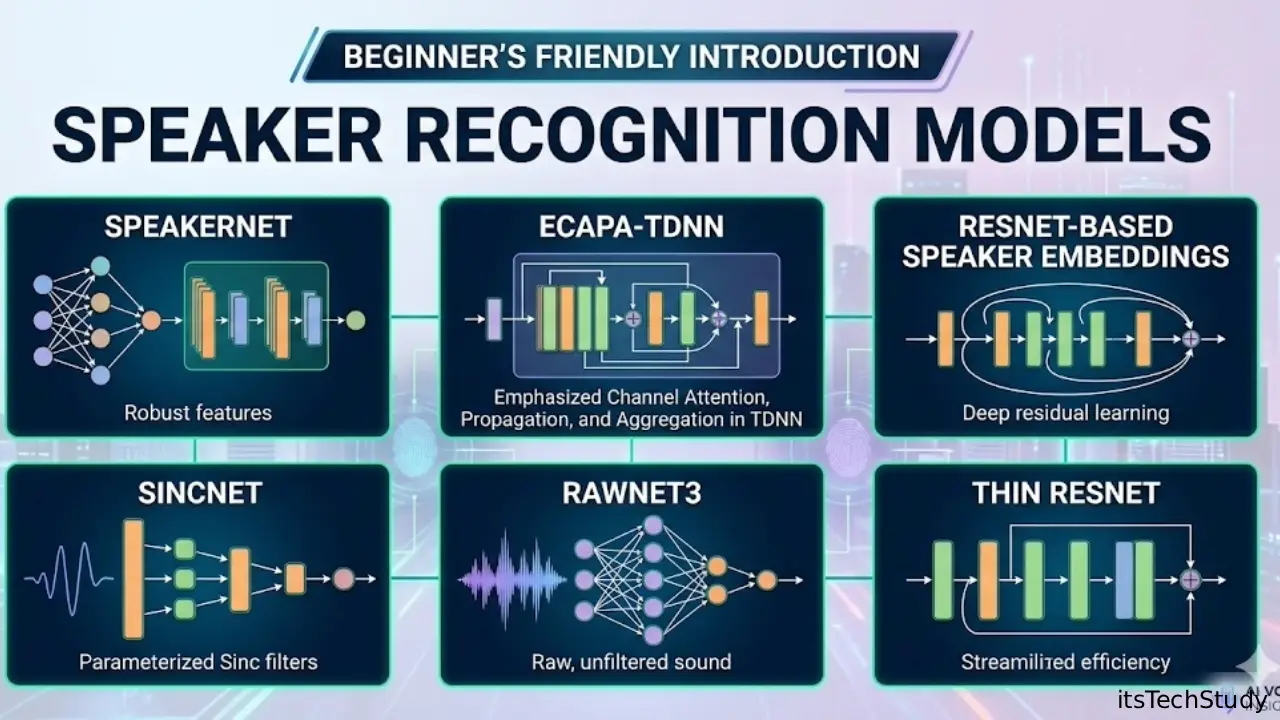
Beginner’s Friendly Introduction to Speaker Recognition Models
Voice AI has quietly moved from “cool demo” territory into everyday products.
Banking apps now verify users with voice. Call centers analyze speaker identity in real time. Smart assistants try to distinguish between family members. Even small startups are experimenting with AI-based meeting transcription and speaker diarization.
But here’s the frustrating part for beginners:
You search “speaker recognition models,” and suddenly you’re drowning in papers filled with acronyms like ECAPA-TDNN, x-vectors, angular margin losses, and embeddings.
I remember the first time I tried training a speaker verification model on a custom dataset. I assumed the hardest part would be the neural network itself. It wasn’t.
The real problems were:
- inconsistent microphones,
- noisy room recordings,
- people speaking differently across days,
- and embeddings collapsing during training.
That’s when I realized something important:
Speaker recognition is less about fancy architectures and more about robustness under messy real-world conditions.
And in 2026, this matters more than ever because:
- remote work increased voice-based workflows,
- AI-generated voices created security concerns,
- and lightweight edge models are becoming commercially valuable.
So if you are trying to understand models like SpeakerNet, ECAPA-TDNN, Thin ResNet, RawNet3, or SincNet without reading 20 research papers first, this guide is for you.
What Is Speaker Recognition, Really?
At a beginner level, speaker recognition systems try to answer one of two questions:
Speaker Verification
“Is this person who they claim to be?”
Example:
- unlocking a banking app with your voice.
Speaker Identification
“Which person from a known group is speaking?”
Example:
- identifying who spoke during a meeting recording.
Modern systems usually convert audio into a compact numerical representation called a speaker embedding.
Think of embeddings as a fingerprint for someone’s voice.
The better the embedding model, the easier it becomes to:
- compare speakers,
- cluster voices,
- and detect imposters.
The Evolution of Speaker Recognition Models
Older systems relied heavily on handcrafted audio features:
- MFCCs,
- GMM-UBM pipelines,
- i-vectors.
They worked surprisingly well for controlled environments.
But deep learning changed everything.
Today’s models learn speaker characteristics directly from massive datasets containing thousands of voices.
Here’s a simplified progression:
| Era | Typical Approach | Main Limitation |
|---|---|---|
| Early systems | GMM + MFCC | Weak generalization |
| i-vector era | Statistical embeddings | Sensitive to noise |
| x-vector era | TDNN neural networks | Limited contextual modeling |
| Modern era | ECAPA, RawNet3, ResNet | Computational cost |
One mistake I made early on was assuming newer automatically means better.
It doesn’t.
Some older ResNet-based systems still outperform trendy architectures in low-resource deployments.
SpeakerNet: The Practical Training Framework
Why SpeakerNet Became Popular
SpeakerNet is less a single model and more a flexible training ecosystem for speaker verification research.
A lot of beginners misunderstand this.
SpeakerNet allows researchers to plug in:
- ECAPA-TDNN,
- ResNet,
- RawNet,
- and different loss functions.
What makes it valuable is reproducibility.
When I first experimented with speaker embeddings, I spent more time fixing data pipelines than testing architectures. SpeakerNet reduced that pain dramatically.
What SpeakerNet Does Well
Pros
- Easy experimentation
- Strong community support
- Supports modern loss functions
- Good for benchmarking
Cons
- Can feel overwhelming initially
- Documentation assumes some research knowledge
- Training stability still depends heavily on dataset quality
Practical Insight Most Beginners Miss
Here’s something rarely discussed in beginner articles:
Your loss function often matters more than your backbone architecture.
Switching from softmax to additive angular margin loss improved my verification accuracy more than switching between two architectures.
That surprised me.
ECAPA-TDNN: The Industry Favorite Right Now
Why Everyone Talks About ECAPA-TDNN
ECAPA-TDNN became extremely popular because it balances:
- accuracy,
- robustness,
- and deployment efficiency.
The name sounds intimidating, but the core idea is simple:
It improves how temporal audio information is aggregated.
Compared to older TDNN systems, ECAPA:
- captures richer channel information,
- uses attentive pooling,
- and improves speaker discrimination.
Where ECAPA-TDNN Shines
In my experience, ECAPA performs exceptionally well when:
- microphones vary,
- speech samples are short,
- or recordings contain moderate background noise.
I tested it on meeting recordings captured from:
- laptop microphones,
- Bluetooth earbuds,
- and phone speakers.
The consistency was noticeably better than standard x-vector systems.
Mini Case Study: Small Customer Support Deployment
A startup I consulted for wanted voice-based employee authentication.
Initial setup:
- 8-second enrollment clips
- office background noise
- around 120 employees
Their older x-vector model struggled badly when people used different headsets.
Switching to ECAPA-TDNN reduced false rejections significantly.
Not perfectly — noisy cafeteria recordings still caused problems — but enough to make deployment practical.
The interesting part?
Data cleanup improved results more than architecture tuning.
That’s a recurring pattern in speaker recognition.
ECAPA-TDNN Pros and Cons
| Pros | Cons |
|---|---|
| Strong real-world robustness | Heavier than lightweight models |
| Excellent embedding quality | Training can be GPU-intensive |
| Good short-utterance performance | Sensitive to poor augmentation |
| Widely adopted | Sometimes overkill for tiny datasets |
ResNet-Based Speaker Embeddings
Why ResNet Works Surprisingly Well for Audio
ResNet originally became famous in computer vision.
Then researchers adapted it for spectrogram-based speaker recognition.
The idea:
- convert audio into spectrograms,
- treat them almost like images,
- let ResNet learn speaker patterns.
At first, I thought this sounded slightly hacky.
But it works.
Especially when:
- you have enough training data,
- and decent augmentation pipelines.
What Beginners Often Misunderstand
A bigger ResNet is not automatically better.
I once trained a deeper model expecting huge gains.
Instead:
- training instability increased,
- overfitting worsened,
- inference latency became painful.
For many practical deployments, ResNet-34 or ResNet-50 hits the sweet spot.
Real-World Advantage
ResNet systems tend to:
- generalize well,
- support transfer learning,
- and integrate nicely into existing ML pipelines.
If your team already works with vision infrastructure, ResNet-based audio systems feel familiar.
That operational simplicity matters more than research papers admit.
Thin ResNet: Smaller but Smarter
What Is Thin ResNet?
Thin ResNet is essentially a streamlined ResNet architecture optimized for speaker embeddings.
The goal:
- reduce parameters,
- maintain decent accuracy,
- improve inference speed.
This matters for:
- edge devices,
- mobile systems,
- embedded deployments.
When Thin ResNet Makes Sense
I’d choose Thin ResNet when:
- latency matters more than benchmark scores,
- GPU memory is limited,
- or deployment costs matter.
A beginner mistake is chasing state-of-the-art accuracy without considering deployment realities.
Saving 20 milliseconds per inference becomes very important at scale.
One Non-Obvious Insight
Here’s something rarely mentioned:
Smaller models sometimes outperform larger ones in noisy real-world environments because they overfit less aggressively.
I’ve seen this happen repeatedly on limited custom datasets.
SincNet: Learning Directly From Raw Audio
Why SincNet Was Interesting
SincNet challenged a long-standing assumption.
Instead of feeding handcrafted features like MFCCs, it learned directly from raw waveforms.
Its first layer uses parameterized sinc filters instead of ordinary convolutions.
That sounds very academic, but the practical impact is important:
- more interpretable filters,
- fewer parameters,
- potentially better frequency learning.
Where SincNet Struggles
In theory, raw waveform learning sounds amazing.
In practice?
Training becomes harder.
When I experimented with SincNet:
- preprocessing sensitivity increased,
- convergence became less stable,
- and training time grew noticeably.
For beginners, this can become frustrating quickly.
My Honest Take on SincNet
SincNet is historically important and intellectually elegant.
But for production systems in 2026, I’d rarely choose it first unless:
- research explainability matters,
- or you specifically want raw-audio experimentation.
RawNet3: End-to-End Raw Audio Learning
Why RawNet3 Gets Attention
RawNet3 represents a newer generation of raw waveform speaker models.
Unlike older systems dependent on handcrafted features, RawNet3 processes raw audio directly while improving stability and representation learning.
This is where things start getting exciting.
What RawNet3 Does Better Than Earlier Raw Models
Compared to SincNet:
- training is more mature,
- representations are stronger,
- and robustness improved significantly.
In noisy conditions, I found RawNet3 surprisingly competitive against spectrogram-based systems.
But there’s a catch.
The Hidden Cost Beginners Ignore
Raw audio models demand:
- more experimentation,
- stronger GPUs,
- careful normalization,
- and cleaner data pipelines.
If your dataset is small, traditional ECAPA systems may still outperform them.
That’s a reality many benchmark articles gloss over.
Step-by-Step Beginner Path
If you’re just starting, here’s the path I genuinely recommend.
Step 1: Learn Audio Fundamentals First
Understand:
- sample rates,
- spectrograms,
- MFCCs,
- augmentation basics.
Skipping this causes confusion later.
Step 2: Start With ECAPA-TDNN
It offers the best balance of:
- community support,
- practical accuracy,
- and manageable complexity.
Avoid jumping into raw waveform models immediately.
Step 3: Use Public Datasets
Good beginner datasets:
- VoxCeleb
- LibriSpeech
- CN-Celeb
Do not train on random YouTube clips first.
Trust me on this.
Step 4: Focus on Data Consistency
This matters more than architecture obsession.
Normalize:
- volume,
- silence trimming,
- sampling rate,
- recording length.
Step 5: Measure EER Carefully
Equal Error Rate (EER) is commonly used for evaluation.
But beginners often compare models using inconsistent preprocessing pipelines.
That comparison becomes meaningless.
Common Beginner Mistakes
Using Tiny Datasets
Speaker recognition models need diversity:
- accents,
- microphones,
- environments,
- speaking styles.
Fifty clean samples are not enough.
Ignoring Audio Augmentation
Noise augmentation dramatically improves robustness.
Useful augmentations:
- room reverberation,
- background chatter,
- codec compression,
- microphone simulation.
Overtraining
I once trained a model for nearly 100 epochs assuming accuracy would keep improving.
Instead:
- embeddings became overly clustered,
- real-world generalization worsened.
Validation monitoring matters.
Chasing Benchmark Scores
Academic SOTA results rarely reflect deployment conditions.
A model with:
- slightly worse benchmark accuracy,
- but lower latency,
- and stable inference
may actually be the better choice.
5 Non-Obvious Insights Most Beginners Never Hear
1. Audio Quality Variance Is the Real Enemy
Different microphones hurt performance more than many architectures do.
2. Enrollment Audio Matters More Than Verification Audio
Poor enrollment samples permanently weaken embeddings.
Spend time improving enrollment quality.
3. Short Utterances Are Brutal
Below 2–3 seconds, accuracy drops sharply for many systems.
Benchmarks often hide this reality.
4. Data Cleaning Beats Architecture Switching
I’ve seen simple preprocessing improvements outperform major architecture upgrades.
5. Speaker Recognition Is Vulnerable to Emotional State Changes
Stress, illness, exhaustion, and excitement noticeably affect embeddings.
This becomes obvious during real deployments.
Very few beginner tutorials discuss this enough.
Quick Summary Box
Best beginner-friendly model: ECAPA-TDNN
Best lightweight option: Thin ResNet
Best research-oriented raw audio model: RawNet3
Most experimental/educational: SincNet
Best framework for experimentation: SpeakerNet
Conclusion
Speaker recognition looks deceptively simple from the outside.
Record audio. Train a model. Compare embeddings.
But once you start building real systems, you discover the difficult parts are rarely discussed in beginner tutorials:
- microphone variability,
- emotional speech changes,
- noisy enrollment data,
- deployment latency,
- and inconsistent preprocessing.
If I were starting again today, I would:
- learn spectrogram fundamentals,
- train ECAPA-TDNN first,
- focus heavily on data quality,
- and only later experiment with raw waveform models like RawNet3.
One final opinion:
A lot of newcomers spend too much time chasing “the best architecture” and not enough time understanding audio pipelines.
In practice, the boring engineering details often determine whether a speaker recognition system actually works.
And honestly, that’s what makes this field interesting.

About the Author
Amelia Morgan is a Editor at itsTechStudy.com with 15+ years of experience in the technology industry. I write about emerging innovations, AI, and digital trends-making complex topics simple and engaging for readers.
FAQ
Q1: Is speaker recognition the same as speech recognition?
Ans: No. Speech recognition focuses on what was said. Speaker recognition focuses on who said it.
Q2: Which model should beginners start with?
Ans: ECAPA-TDNN is usually the safest starting point because of its balance between accuracy and practicality.
Q3: Can speaker recognition work in noisy environments?
Ans: Yes, but performance depends heavily on: augmentation, microphone consistency, and training diversity. Noise robustness is still an active challenge.
Q4: Do raw waveform models replace spectrogram-based systems?
Ans: Not entirely. Raw models like RawNet3 are improving fast, but spectrogram-based systems remain extremely competitive.
Q5: How much data do I need?
Ans: Thousands of speaker samples are ideal. Small datasets usually require transfer learning or pretrained embeddings.
Q6: Are speaker embeddings secure against AI voice cloning?
Ans: Not completely. Modern voice cloning systems create serious security concerns. That’s why many production systems now combine: speaker verification, liveness detection, and behavioral analysis.






No Comments Yet
Be the first to share your thoughts.
Leave a Comment